Одной из важнейших задач интернет-маркетологов является помочь поисковым системам ответить на вопрос «Чему посвящена эта страница?». Поисковые роботы не умеют читать веб-страницы, как это делает человек — в этом им помогает особенная структура и подсказки.
Понимание принципов работы поисковых систем поможет обеспечить страницам более мощный сигнал и, соответственно, вывести их на более высокие позиции. В данной статье описаны техники внутренней оптимизации, совмещая которые, можно добиться выдающихся результатов.
Так как Google не раскрывает секреты построения своих алгоритмов, данная информация собиралась на протяжении многих лет на основе различных интервью, исследовательских опусов, патентах и наблюдений опытных маркетологов.
Однако следует помнить, что приемы, описанные ниже, не являются истиной в последней инстанции! Google наверняка имеет еще множество путей определения релевантности страниц, поэтому экспериментируйте!
Итак, начнем по порядку.
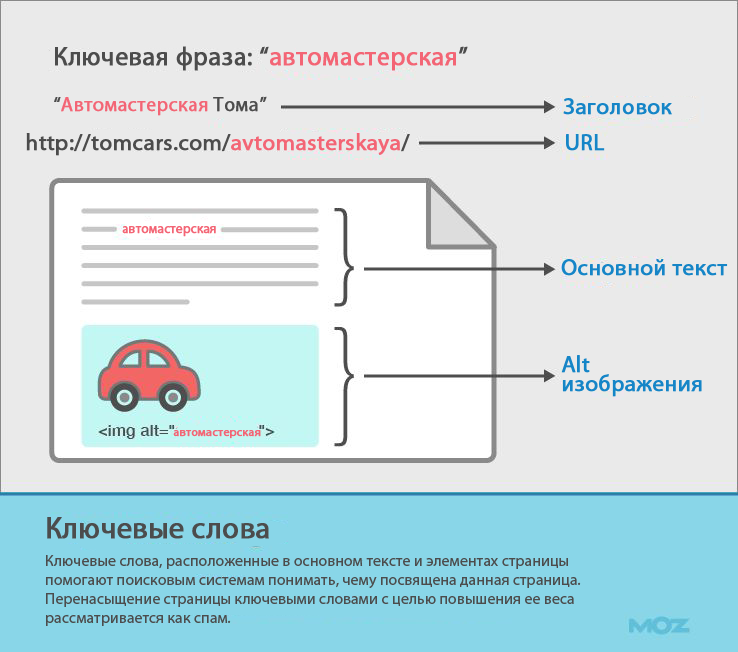
Используемые ключевые слова
Вначале были ключевые слова.
Принцип был следующим: если ваша страница посвящена определенной теме, поисковые роботы обнаружат ключевые слова в важных местах, таких как тег title, заголовки, атрибуты «альт» для изображений, а также в самом тексте. SEO-специалисты продвигали странички, размещая в них ключевые слова.
Даже теперь оптимизация страницы под ключевые запросы является первым шагом в процессе SEO-оптимизации.
Большинство из инструментов продвижения по-прежнему основываются на ключевых словах, однако согласно последним исследованиям, .
Таким образом, нельзя просто поместить на страницу нужные «ключевики» и надеяться, что этого будет достаточно для попадания странички в топ.
TF-IDF
В оптимизации решает не частота ключевых слов на странице, а такая статистическая мера, как TF-IDF (от английского TF — term frequency (частота слова), IDF — inverse document frequency (обратная частота документа).
Исследователи Google не так давно меру TF-IDF как «давно используемую для индексации веб-страниц». Разновидности меры TF-IDF также числятся компонентом в некоторых известных
Мера TF-IDF не показывает частоту употребления слова, а измеряет его значимость путем сравнения частоты его употребления с ожиданиями, составленными на основе коллекции документов.
Если мы сравним слова “basket” («корзина») и “basketball player” («баскетболист») в сервисе , мы увидим, что “basketball player” встречается гораздо реже, чем “basket”. Основываясь на частоте употребления, можно сделать вывод, что фраза “basketball player” гораздо важнее для содержащей его страницы, в то время как порог значимости для “basket” гораздо выше.
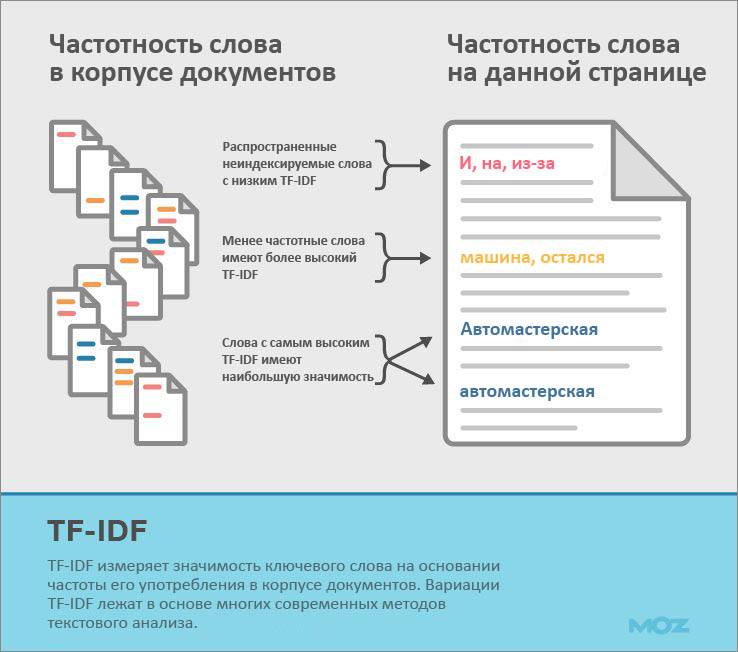
Изучив взаимосвязь показателя TF-IDF с , можно заметить, что его влияние на результат поисковой выдачи лишь немного больше, чем использование ключевых слов. Другими словами, сам по себе высокий результат TF-IDF не играет ключевой роли в продвижении — только как компонент целого процесса оптимизации.
Синонимы и близкие по значению слова
Google обрабатывает более 6 миллионов запросов в день обладает огромной базой данных, чтобы распознать, что действительно подразумевает пользователь под своим поисковым запросом. По результатам собственного исследования Google, синонимы используются в около .
Дабы избежать путаницы, поисковые системы имеют в своем «арсенале» огромное количество синонимов и близких по смыслу слов к миллиардам фраз. Именно благодаря этому пользователь может найти ваш сайт, даже если изначально вбил в строку поиска ключевое слово, отсутствующее на страницах. Возьмем, к примеру, фразу , которая может означать то же самое, что и:
• Фото собак
• Изображения собак
• Картинки с собаками
• Фотки собак
• Фотки с собаками
С точки зрения SEO, это значит, что контент должен быть написан естественным языком с применением синонимов и близких по значению слов, вместо того, чтобы повторять одно и то же ключевое слово или фразу по всему тексту.

Использование вариаций на ваши основные темы добавит также более глубокое семантическое значение и поможет решить проблему многозначности, когда одно и то же ключевое слово относится к нескольким тематикам. Например, слово “plant” («завод») в сочетании с синонимом “factory” («фабрика») явно относится к теме производства, в то время как “plant” в сочетании с “shrub” («куст») уже будет значить «растение» и относиться к теме «растительность».
Актуальный («Колибри») также использует параметр сочетаемости для замены поисковых запросов.
В рамках алгоритма Hummingbird параметр сочетаемости используется для выявления слов, которые могут быть синонимами в определенном контексте. Google может использовать синоним и правила эквивалентного запроса в сочетании с анализом других слов, не отбрасывая их в самом запросе, чтобы понять контекст термина запроса и возможную замену для него, чтобы перефразировать или поменять термины поиска и показать лучшие результаты.
Билл Славски,
Сегментация страницы
То, где на странице размещаются ключевые слова, порой важнее самих слов.
Каждая веб-страница состоит из нескольких частей — заголовков, футера, боковых колонок. Поисковые системы уже давно работают над определением самой важной части страницы. Microsoft и Google владеют , по которым контент в более важный секциях HTML-кода имеет больший вес.
Текст, размещенный в основном тексте, более важен, чем текст, размещенный в боковых секциях или любых других позициях.
Значимость сегментация текста возрастает при отображении на мобильных устройствах, где многие части странички скрыты. Поисковые системы стремятся приподнести пользователю именно видимые страницы с важной информацией, поэтому текст в таких секциях заслуживает наибольшего внимания.
HTML5 идет еще дальше и предлагает использовать дополнительные , такие как <article>, <aside> и <nav>, которые четко выделяют сегменты вашей веб-странички.
Семантическое расстояние и отношения между словами
В контексте поисковой оптимизации семантическое расстояние означает отношение между различными словами и фразами в тексте. Семантическое расстояние отличается от физического и характеризует связь слов в пределах предложения, абзаца и HTML-элементов.
Например, как поисковая система поймет, что слово «Лабрадор» относится к «породе собак», если эти две фразы не расположены в одном предложении?
Поисковики решают данную проблему путем измерения расстояния между различными словами и фразами в пределах HTML-элементов. Чем меньше семантическое расстояние, тем больше вероятность, что эти слова связаны по смыслу. Связь между фразами, расположенными в одном и том же абзаце, теснее, чем если их разделяет несколько блоков текста.
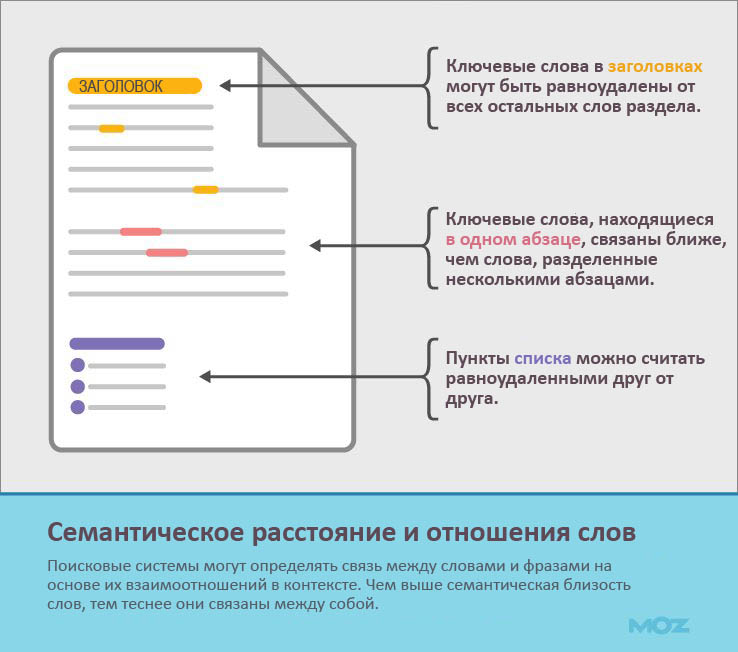
Кроме этого, посредством HTML-элементов можно сокращать семантическое расстояние между понятиями, притягивая их ближе друг к другу. Например, пункты списка считаются равноудаленными друг от друга, а .
Пришло время упомянуть такой сервис, как Schema.org. помогает структурировать текст так, чтобы отношения между словами были определены эксплицитно.
Огромным преимуществом Schema является то, что она не заставляет поисковики строить догадки — отношения четко определены. Однако в то же время она требует от вебмастеров специфичную разметку. На сегодняшний день исследования показывают, что данный компонент оптимизации не получил .
Совместная встречаемость и фразовое индексирование
Ранее мы обсуждали отдельные ключевые слова и отношения между ними. Поисковые системы также используют методы индексирования страниц на основе полноценных фраз, а также ранжируют страницы по их релевантности.
Данный процесс известен как .
Самое интересное в этом процессе не то, каким образом Google определяет ключевые фразы на странице, а то, как он вычисляет важность этих фраз для ранжирования страницы.
Применяя принцип совместной встречаемости поисковики понимают, как конкретные фразы могут предсказывать появление в тексте других фраз. Например, если вашим запросом является «Джон Оливер», то эта фраза часто появляется в текстах вместе с «HBO», «Daily Show», «комик». И страница, содержащая данные фразы, имеет больше шансов быть посвященной «Джону Оливеру», чем страница без оных.
Добавьте к этому входящие ссылки со страниц, содержащих подобные, совместно встречающиеся фразы, и вы обеспечите своей странице мощные контекстуальные сигналы.
Выделенность объекта
Заглядывая в будущее, поисковые системы уже сейчас исследуют способы использования отношений не просто между ключевыми словами, а целыми объектами для определения тематической релевантности.
Один из таких приемов, упомянутых в исследовании Google, описывает определение релевантности через .
Прием, учитывающий выделенность объекта, идет дальше, чем традиционные приемы ключевых слов (например, TF-IDF) и для поиска релевантных ключевых слов руководствуется уже известными отношениями между объектами. Объект в тексте — это часть документа, которая легко заметна и определена.
Чем крепче связь объекта с другими объектами на странице, тем выше релевантность.
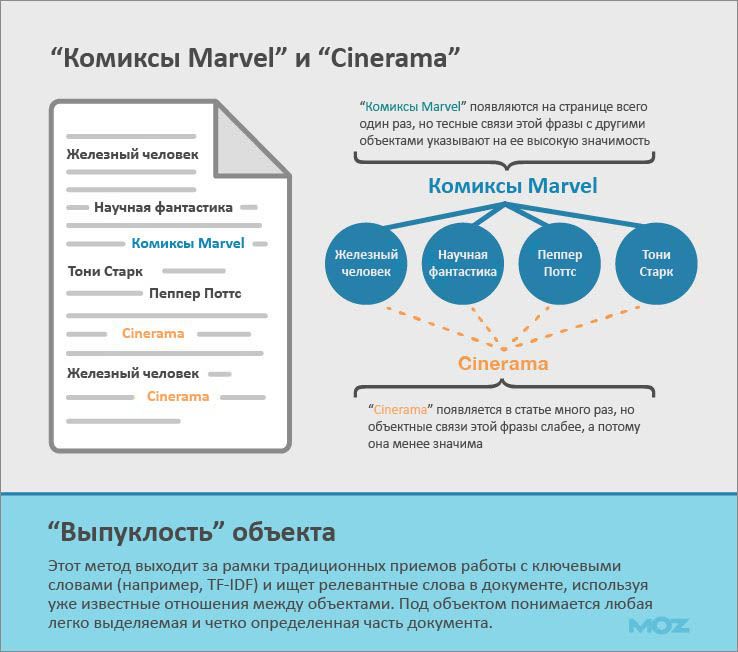
В инфографике выше проиллюстрирован документ, содержащий темы «Железный человек», «Тони Старк», «Пеппер Потс» и «фантастика». Фраза «комиксы «Марвел» имеет сильную объектную связь с каждой из этих тем, поэтому даже будучи упомянутой в тексте один раз, она будет иметь высокую степень важности.
С другой стороны, даже несмотря на то, что фраза «Синерама» встречается в тексте не единожды (это название кинотеатра, в котором показывают фильм), она имеет слабое объектное отношение с темами и поэтому не обладает высокой релевантностью.
Практические советы для успешной SEO-оптимизации
Рассмотренные выше продвинутые техники тематического таргетирования теперь можно с легкостью применять к работе с контентом. А поскольку многие из нас все-таки не имеют средств верно высчитать семантические и объектные отношения, предлагаем набор простых шагов на пути к оптимизированному контенту:
- В основе всего лежат ключевые слова. Тщательный анализ поможет вам понять, с какими ключевыми словами вам лучше работать, узнать их популярность и . Ваша главная цель — связать контент страницы с теми же самыми запросами, которые люди вбивают в строку поиска.
- Анализируйте схожие тематики. Отойдите от анализа отдельно взятых ключевых слов, сосредоточившись вместо этого на . Найдите второстепенные ключевики, имеющие отношения к каждому из ваших слов. Какие фразы люди используют, обсуждая вашу тематику? О чем они говорят? Включение в текст тематически сходных фраз поможет построить контент вокруг центральной темы.
- Созданный контент должен давать ответы на большинство вопросов. Если ваша страница оказалась на самой высокой позиции, значит, по мнению поисковых систем, она лучше других отвечает на заданный пользователем вопрос. Структурируя контент вокруг определенной темы, убедитесь, что он поможет пользователю лучше, чем конкуренты.
- Используйте естественный язык и синонимы. Исследуя ключевые слова по вашей тематике, обратите внимание на используемые пользователями синонимичные запросы и включите их в свой текст. в этом процессе бесценен.
- Располагайте важный контент в правильных местах. Избегайте футеров и боковых секций. Не пытайтесь «надуть» поисковики причудливым CSS и JavaScript-трюками. Ваша релевантная информация должна располагаться в хорошо заметных и доступных пользователю частях страницы.
- Правильно структурируйте контент. Заголовки, абзацы, списки и таблицы обеспечивают тексту структуру, позволяя поисковикам понять тематическое таргетирование. Правильная веб-страница обладает такой же структурой, что и качественная университетская газета. Поэтому не забывайте о введении, заключении, полного раскрытия тематики, разделения на абзацы, грамматику и ссылки на источники.
В конечном счете, нам не нужен супер-компьютер, чтобы сделать наш контент лучше и понятным поисковым системам и пользователям. Если мы пишем по-человечески и для людей, непреодолимых трудностей с SEO-оптимизацией не возникнет.











